Design a URL Shortening service like TinyURL
Let’s design a URL shortening service like TinyURL. This service will provide short aliases redirecting to long URLs. Similar services: bit.ly, goo.gl, qlink.me 8, etc. Difficulty Level: Easy
- Why do we need URL shortening?
URL shortening is used to create shorter aliases for long URLs. We call these shortened aliases “short links.” Users are redirected to the original URL when they hit these short links. Short links save a lot of space when displayed, printed, messaged or tweeted. Additionally, users are less likely to mistype shorter URLs.
For example, if we shorten this page through TinyURL:
https://www.someexample.com/views/5668639101419520/5649050225344512/5668600916475904/ 46
We would get:
The shortened URL is nearly one-third of the size of the actual URL.
URL shortening is used for optimizing links across devices, tracking individual links to analyze audience and campaign performance, and hiding affiliated original URLs.
If you haven’t used tinyurl.com 35 before, please try creating a new shortened URL and spend some time going through the various options their service offers. This will help you a lot in understanding this chapter better.
- Requirements and Goals of the System
 You should always clarify requirements at the beginning of the interview. Be sure to ask questions to find the exact scope of the system that the interviewer has in mind.
You should always clarify requirements at the beginning of the interview. Be sure to ask questions to find the exact scope of the system that the interviewer has in mind.
Our URL shortening system should meet the following requirements:
Functional Requirements:
- Given a URL, our service should generate a shorter and unique alias of it. This is called a short link.
- When users access a short link, our service should redirect them to the original link.
- Users should optionally be able to pick a custom short link for their URL.
- Links will expire after a standard default timespan. Users should also be able to specify the expiration time.
Non-Functional Requirements:
- The system should be highly available. This is required because, if our service is down, all the URL redirections will start failing.
- URL redirection should happen in real-time with minimal latency.
- Shortened links should not be guessable (not predictable).
Extended Requirements:
- Analytics; e.g., how many times a redirection happened?
- Our service should also be accessible through REST APIs by other services.
- Capacity Estimation and Constraints
Our system will be read-heavy. There will be lots of redirection requests compared to new URL shortenings. Let’s assume 100:1 ratio between read and write.
Traffic estimates: If we assume we will have 500M new URL shortenings per month, we can expect (100 * 500M => 50B) redirections during that same period. What would be Queries Per Second (QPS) for our system?
New URLs shortenings per second:
500 million / (30 days * 24 hours * 3600 seconds) = ~200 URLs/s
URLs redirections per second, considering 100:1 read/write ratio:
50 billion / (30 days * 24 hours * 3600 sec) = ~19K/s
Storage estimates: Let’s assume we store every URL shortening request (and associated shortened link) for 5 years. Since we expect to have 500M new URLs every month, the total number of objects we expect to store will be 30 billion:
500 million * 5 years * 12 months = 30 billion
Let’s assume that each stored object will be approximately 500 bytes (just a ballpark estimate–we will dig into it later). We will need 15TB of total storage:
Bandwidth estimates: For write requests, since we expect 200 new URLs every second, total incoming data for our service will be 100KB per second:
200 * 500 bytes = 100 KB/s
For read requests, since every second we expect ~19K URLs redirections, total outgoing data for our service would be 9MB per second.
19K * 500 bytes = ~9 MB/s
Memory estimates: If we want to cache some of the hot URLs that are frequently accessed, how much memory will we need to store them? If we follow the 80-20 rule, meaning 20% of URLs generate 80% of traffic, we would like to cache these 20% hot URLs.
Since we have 19K requests per second, we will be getting 1.7 billion requests per day:
19K * 3600 seconds * 24 hours = ~1.7 billion
To cache 20% of these requests, we will need 170GB of memory.
0.2 * 1.7 billion * 500 bytes = ~170GB
High level estimates: Assuming 500 million new URLs per month and 100:1 read:write ratio, following is the summary of the high level estimates for our service:
| New URLs | 200/s |
|---|---|
| URL redirections | 19K/s |
| Incoming data | 100KB/s |
| Outgoing data | 9MB/s |
| Storage for 5 years | 15TB |
| Memory for cache | 170GB |
- System APIs
Once we’ve finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system.
We can have SOAP or REST APIs to expose the functionality of our service. Following could be the definitions of the APIs for creating and deleting URLs:
creatURL(api_dev_key, original_url, custom_alias=None, user_name=None, expire_date=None)
Parameters:
api_dev_key (string): The API developer key of a registered account. This will be used to, among other things, throttle users based on their allocated quota.
original_url (string): Original URL to be shortened.
custom_alias (string): Optional custom key for the URL.
user_name (string): Optional user name to be used in encoding.
expire_date (string): Optional expiration date for the shortened URL.
api_dev_key (string): The API developer key of a registered account. This will be used to, among other things, throttle users based on their allocated quota.
original_url (string): Original URL to be shortened.
custom_alias (string): Optional custom key for the URL.
user_name (string): Optional user name to be used in encoding.
expire_date (string): Optional expiration date for the shortened URL.
Returns: (string)
A successful insertion returns the shortened URL; otherwise, it returns an error code.
A successful insertion returns the shortened URL; otherwise, it returns an error code.
deleteURL(api_dev_key, url_key)
Where “url_key” is a string representing the shortened URL to be retrieved. A successful deletion returns ‘URL Removed’.
How do we detect and prevent abuse? A malicious user can put us out of business by consuming all URL keys in the current design. To prevent abuse, we can limit users via their api_dev_key. Each api_dev_key can be limited to a certain number of URL creations and redirections per some time period (which may be set to a different duration per developer key).
- Database Design
Defining the DB schema in the early stages of the interview would help to understand the data flow among various components and later would guide towards the data partitioning.A few observations about the nature of the data we will store:- We need to store billions of records.
- Each object we store is small (less than 1K).
- There are no relationships between records—other than storing which user created a URL.
- Our service is read-heavy.
Database Schema:
We would need two tables: one for storing information about the URL mappings, and one for the user’s data who created the short link.


What kind of database should we use? Since we anticipate storing billions of rows, and we don’t need to use relationships between objects – a NoSQL key-value store like Dynamo or Cassandra is a better choice. A NoSQL choice would also be easier to scale. Please see SQL vs NoSQL 84 for more details.
- Basic System Design and Algorithm
The problem we are solving here is: how to generate a short and unique key for a given URL?
In the TinyURL example in Section 1, the shortened URL is “http://tinyurl.com/jlg8zpc” 6. The last six characters of this URL is the short key we want to generate. We’ll explore two solutions here:
a. Encoding actual URL
We can compute a unique hash (e.g., MD5 11 or SHA256 13, etc.) of the given URL. The hash can then be encoded for displaying. This encoding could be base36 ([a-z ,0-9]) or base62 ([A-Z, a-z, 0-9]) and if we add ‘-’ and ‘.’, we can use base64 encoding. A reasonable question would be: what should be the length of the short key? 6, 8 or 10 characters?
Using base64 encoding, a 6 letter long key would result in 64^6 = ~68.7 billion possible strings
Using base64 encoding, an 8 letter long key would result in 64^8 = ~281 trillion possible strings
Using base64 encoding, an 8 letter long key would result in 64^8 = ~281 trillion possible strings
With 68.7B unique strings, let’s assume for our system six letter keys would suffice.
If we use the MD5 algorithm as our hash function, it’ll produce a 128-bit hash value. After base64 encoding, we’ll get a string having more than 21 characters (since each base64 character encodes 6 bits of the hash value). Since we only have space for 8 characters per short key, how will we choose our key then? We can take the first 6 (or 8) letters for the key. This could result in key duplication though, upon which we can choose some other characters out of the encoding string or swap some characters.
What are different issues with our solution? We have the following couple of problems with our encoding scheme:
- If multiple users enter the same URL, they can get the same shortened URL, which is not acceptable.
- What if parts of the URL are URL-encoded? e.g., http://www.educative.io/distributed.php?id=design 7, and http://www.educative.io/distributed.php%3Fid%3Ddesign 4 are identical except for the URL encoding.
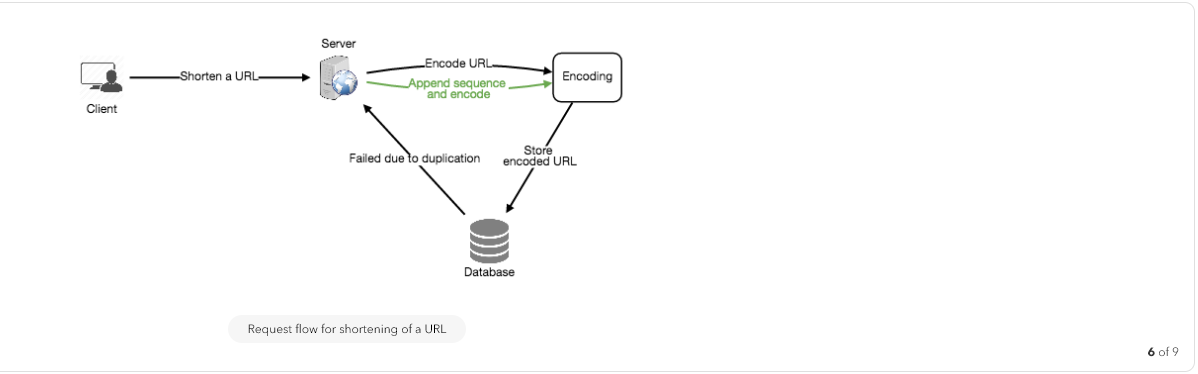
Workaround for the issues: We can append an increasing sequence number to each input URL to make it unique, and then generate a hash of it. We don’t need to store this sequence number in the databases, though. Possible problems with this approach could be an ever-increasing sequence number. Can it overflow? Appending an increasing sequence number will also impact the performance of the service.
Another solution could be to append user id (which should be unique) to the input URL. However, if the user has not signed in, we would have to ask the user to choose a uniqueness key. Even after this, if we have a conflict, we have to keep generating a key until we get a unique one.
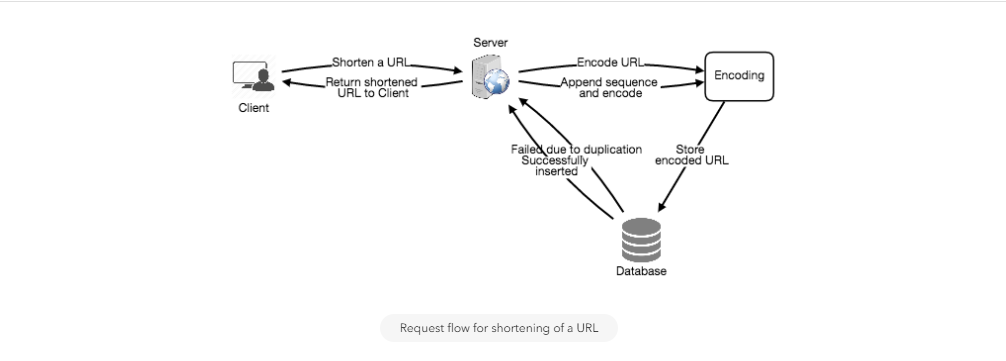

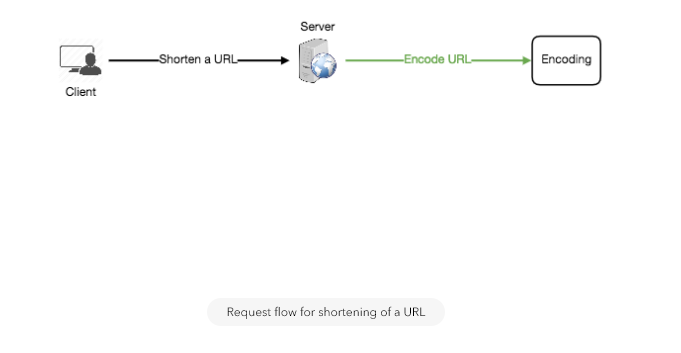
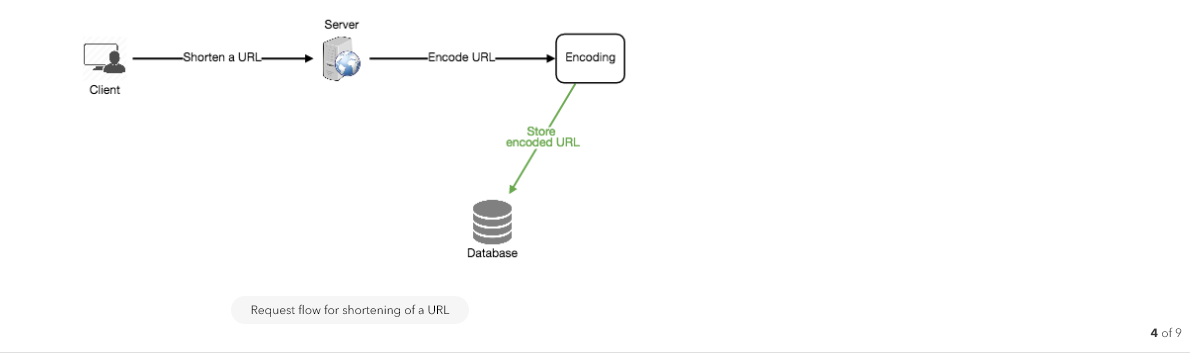
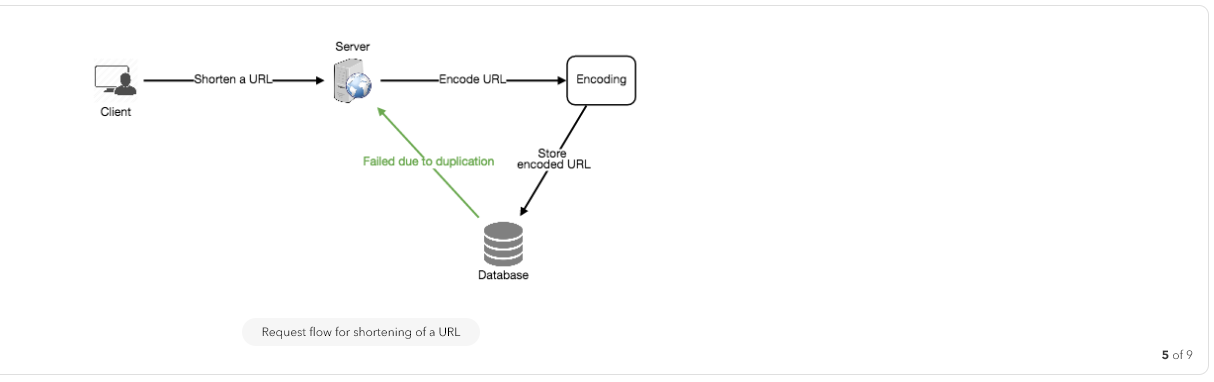

b. Generating keys offline
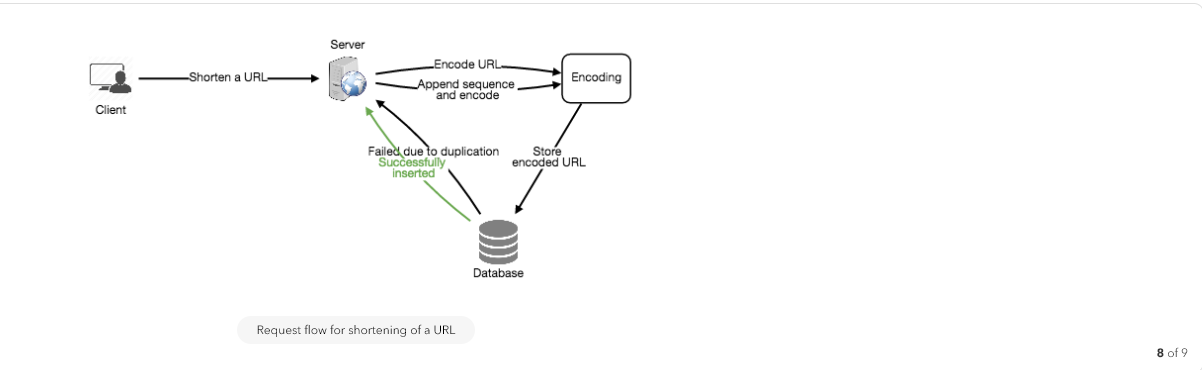
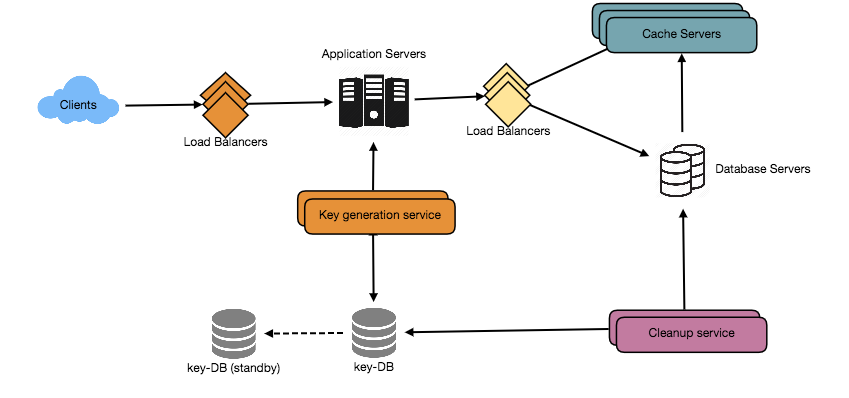
We can have a standalone Key Generation Service (KGS) that generates random six letter strings beforehand and stores them in a database (let’s call it key-DB). Whenever we want to shorten a URL, we will just take one of the already-generated keys and use it. This approach will make things quite simple and fast. Not only are we not encoding the URL, but we won’t have to worry about duplications or collisions. KGS will make sure all the keys inserted into key-DB are unique
Can concurrency cause problems? As soon as a key is used, it should be marked in the database to ensure it doesn’t get used again. If there are multiple servers reading keys concurrently, we might get a scenario where two or more servers try to read the same key from the database. How can we solve this concurrency problem?
Servers can use KGS to read/mark keys in the database. KGS can use two tables to store keys: one for keys that are not used yet, and one for all the used keys. As soon as KGS gives keys to one of the servers, it can move them to the used keys table. KGS can always keep some keys in memory so that it can quickly provide them whenever a server needs them.
For simplicity, as soon as KGS loads some keys in memory, it can move them to the used keys table. This ensures each server gets unique keys. If KGS dies before assigning all the loaded keys to some server, we will be wasting those keys–which is acceptable, given the huge number of keys we have.
KGS also has to make sure not to give the same key to multiple servers. For that, it must synchronize (or get a lock to) the data structure holding the keys before removing keys from it and giving them to a server
What would be the key-DB size? With base64 encoding, we can generate 68.7B unique six letters keys. If we need one byte to store one alpha-numeric character, we can store all these keys in:
6 (characters per key) * 68.7B (unique keys) = 412 GB.
Isn’t KGS the single point of failure? Yes, it is. To solve this, we can have a standby replica of KGS. Whenever the primary server dies, the standby server can take over to generate and provide keys.
Can each app server cache some keys from key-DB? Yes, this can surely speed things up. Although in this case, if the application server dies before consuming all the keys, we will end up losing those keys. This could be acceptable since we have 68B unique six letter keys.
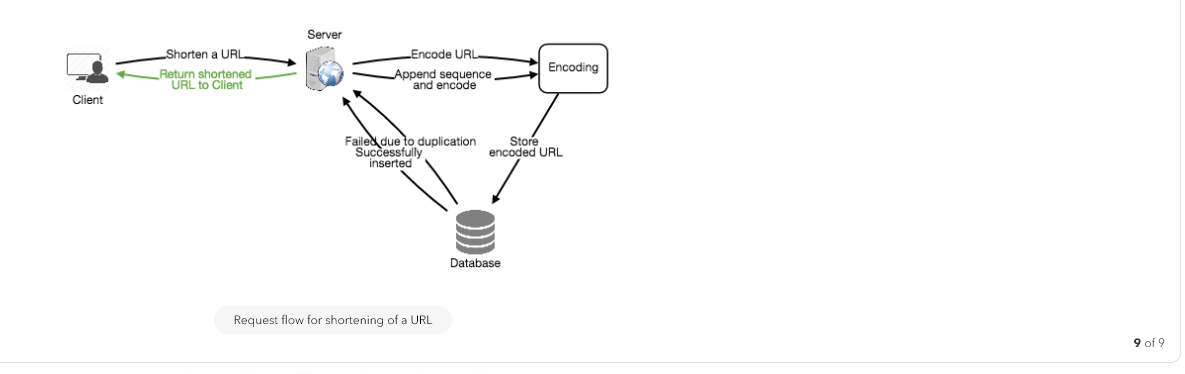
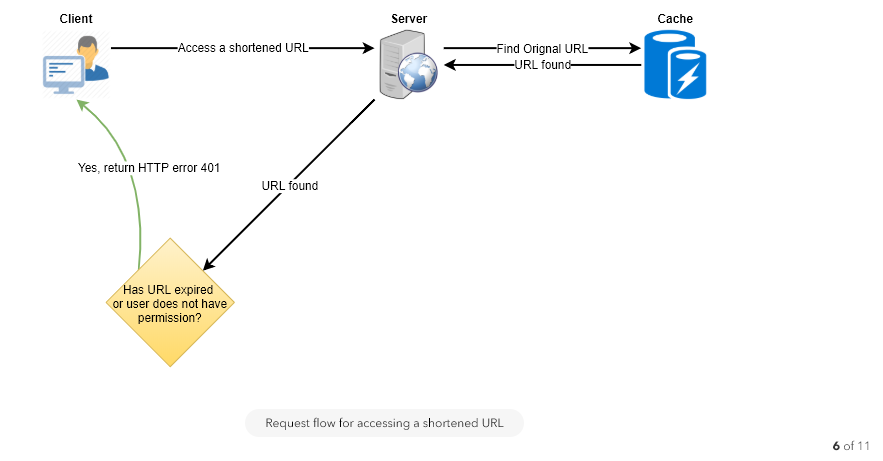
How would we perform a key lookup? We can look up the key in our database or key-value store to get the full URL. If it’s present, issue an “HTTP 302 Redirect” status back to the browser, passing the stored URL in the “Location” field of the request. If that key is not present in our system, issue an “HTTP 404 Not Found” status, or redirect the user back to the homepage.
Should we impose size limits on custom aliases? Our service supports custom aliases. Users can pick any ‘key’ they like, but providing a custom alias is not mandatory. However, it is reasonable (and often desirable) to impose a size limit on a custom alias to ensure we have a consistent URL database. Let’s assume users can specify a maximum of 16 characters per customer key (as reflected in the above database schema).

High level system design for URL shortening
- Data Partitioning and Replication
To scale out our DB, we need to partition it so that it can store information about billions of URLs. We need to come up with a partitioning scheme that would divide and store our data to different DB servers.
a. Range Based Partitioning: We can store URLs in separate partitions based on the first letter of the URL or the hash key. Hence we save all the URLs starting with letter ‘A’ in one partition, save those that start with letter ‘B’ in another partition and so on. This approach is called range-based partitioning. We can even combine certain less frequently occurring letters into one database partition. We should come up with a static partitioning scheme so that we can always store/find a file in a predictable manner.
The main problem with this approach is that it can lead to unbalanced servers. For example: we decide to put all URLs starting with letter ‘E’ into a DB partition, but later we realize that we have too many URLs that start with letter ‘E’.
b. Hash-Based Partitioning: In this scheme, we take a hash of the object we are storing. We then calculate which partition to use based upon the hash. In our case, we can take the hash of the ‘key’ or the actual URL to determine the partition in which we store the data object.
Our hashing function will randomly distribute URLs into different partitions (e.g., our hashing function can always map any key to a number between [1…256]), and this number would represent the partition in which we store our object.
This approach can still lead to overloaded partitions, which can be solved by using Consistent Hashing 37.
- Cache
We can cache URLs that are frequently accessed. We can use some off-the-shelf solution like Memcache, which can store full URLs with their respective hashes. The application servers, before hitting backend storage, can quickly check if the cache has the desired URL.
How much cache should we have? We can start with 20% of daily traffic and, based on clients’ usage pattern, we can adjust how many cache servers we need. As estimated above, we need 170GB memory to cache 20% of daily traffic. Since a modern day server can have 256GB memory, we can easily fit all the cache into one machine. Alternatively, we can use a couple of smaller servers to store all these hot URLs.
Which cache eviction policy would best fit our needs? When the cache is full, and we want to replace a link with a newer/hotter URL, how would we choose? Least Recently Used (LRU) can be a reasonable policy for our system. Under this policy, we discard the least recently used URL first. We can use a Linked Hash Map 16 or a similar data structure to store our URLs and Hashes, which will also keep track of which URLs are accessed recently.
To further increase the efficiency, we can replicate our caching servers to distribute load between them.
How can each cache replica be updated? Whenever there is a cache miss, our servers would be hitting a backend database. Whenever this happens, we can update the cache and pass the new entry to all the cache replicas. Each replica can update their cache by adding the new entry. If a replica already has that entry, it can simply ignore it.
- Load Balancer (LB)
We can add a Load balancing layer at three places in our system:
- Between Clients and Application servers
- Between Application Servers and database servers
- Between Application Servers and Cache servers
Initially, we could use a simple Round Robin approach that distributes incoming requests equally among backend servers. This LB is simple to implement and does not introduce any overhead. Another benefit of this approach is, if a server is dead, LB will take it out of the rotation and will stop sending any traffic to it.
A problem with Round Robin LB is that server load is not taken into consideration. If a server is overloaded or slow, the LB will not stop sending new requests to that server. To handle this, a more intelligent LB solution can be placed that periodically queries the backend server about its load and adjusts traffic based on that.
- Purging or DB cleanup
Should entries stick around forever or should they be purged? If a user-specified expiration time is reached, what should happen to the link?
If we chose to actively search for expired links to remove them, it would put a lot of pressure on our database. Instead, we can slowly remove expired links and do a lazy cleanup. Our service will make sure that only expired links will be deleted, although some expired links can live longer but will never be returned to users.
- Whenever a user tries to access an expired link, we can delete the link and return an error to the user.
- A separate Cleanup service can run periodically to remove expired links from our storage and cache. This service should be very lightweight and can be scheduled to run only when the user traffic is expected to be low.
- We can have a default expiration time for each link (e.g., two years).
- After removing an expired link, we can put the key back in the key-DB to be reused.
- Should we remove links that haven’t been visited in some length of time, say six months? This could be tricky. Since storage is getting cheap, we can decide to keep links forever.
- Telemetry
How many times a short URL has been used, what were user locations, etc.? How would we store these statistics? If it is part of a DB row that gets updated on each view, what will happen when a popular URL is slammed with a large number of concurrent requests?
Some statistics worth tracking: country of the visitor, date and time of access, web page that refers the click, browser or platform from where the page was accessed.
- Security and Permissions
Can users create private URLs or allow a particular set of users to access a URL?
We can store permission level (public/private) with each URL in the database. We can also create a separate table to store UserIDs that have permission to see a specific URL. If a user does not have permission and tries to access a URL, we can send an error (HTTP 401) back. Given that we are storing our data in a NoSQL wide-column database like Cassandra, the key for the table storing permissions would be the ‘Hash’ (or the KGS generated ‘key’). The columns will store the UserIDs of those users that have permissions to see the URL.
Designing Pastebin
Let’s design a Pastebin like web service, where users can store plain text. Users of the service will enter a piece of text and get a randomly generated URL to access it. Similar Services: pastebin.com 16, pasted.co 1, chopapp.com 3 Difficulty Level: Easy
- What is Pastebin?
Pastebin like services enable users to store plain text or images over the network (typically the Internet) and generate unique URLs to access the uploaded data. Such services are also used to share data over the network quickly, as users would just need to pass the URL to let other users see it.
If you haven’t used pastebin.com 14 before, please try creating a new ‘Paste’ there and spend some time going through different options their service offers. This will help you a lot in understanding this chapter better.
- Requirements and Goals of the System
Our Pastebin service should meet the following requirements:
Functional Requirements:
- Users should be able to upload or “paste” their data and get a unique URL to access it.
- Users will only be able to upload text.
- Data and links will expire after a specific timespan automatically; users should also be able to specify expiration time.
- Users should optionally be able to pick a custom alias for their paste.
Non-Functional Requirements:
- The system should be highly reliable, any data uploaded should not be lost.
- The system should be highly available. This is required because if our service is down, users will not be able to access their Pastes.
- Users should be able to access their Pastes in real-time with minimum latency.
- Paste links should not be guessable (not predictable).
Extended Requirements:
- Analytics, e.g., how many times a paste was accessed?
- Our service should also be accessible through REST APIs by other services.
- Some Design Considerations
Pastebin shares some requirements with URL Shortening service 118, but there are some additional design considerations we should keep in mind.
What should be the limit on the amount of text user can paste at a time? We can limit users not to have Pastes bigger than 10MB to stop the abuse of the service.
Should we impose size limits on custom URLs? Since our service supports custom URLs, users can pick any URL that they like, but providing a custom URL is not mandatory. However, it is reasonable (and often desirable) to impose a size limit on custom URLs, so that we have a consistent URL database.
- Capacity Estimation and Constraints
Our services will be read-heavy; there will be more read requests compared to new Pastes creation. We can assume a 5:1 ratio between read and write.
Traffic estimates: Pastebin services are not expected to have traffic similar to Twitter or Facebook, let’s assume here that we get one million new pastes added to our system every day. This leaves us with five million reads per day.
New Pastes per second:
1M / (24 hours * 3600 seconds) ~= 12 pastes/sec
Paste reads per second:
5M / (24 hours * 3600 seconds) ~= 58 reads/sec
Storage estimates: Users can upload maximum 10MB of data; commonly Pastebin like services are used to share source code, configs or logs. Such texts are not huge, so let’s assume that each paste on average contains 10KB.
At this rate, we will be storing 10GB of data per day.
1M * 10KB => 10 GB/day
If we want to store this data for ten years, we would need the total storage capacity of 36TB.
With 1M pastes every day we will have 3.6 billion Pastes in 10 years. We need to generate and store keys to uniquely identify these pastes. If we use base64 encoding ([A-Z, a-z, 0-9, ., -]) we would need six letters strings:
64^6 ~= 68.7 billion unique strings
If it takes one byte to store one character, total size required to store 3.6B keys would be:
3.6B * 6 => 22 GB
22GB is negligible compared to 36TB. To keep some margin, we will assume a 70% capacity model (meaning we don’t want to use more than 70% of our total storage capacity at any point), which raises our storage needs to 51.4TB.
Bandwidth estimates: For write requests, we expect 12 new pastes per second, resulting in 120KB of ingress per second.
12 * 10KB => 120 KB/s
As for the read request, we expect 58 requests per second. Therefore, total data egress (sent to users) will be 0.6 MB/s.
58 * 10KB => 0.6 MB/s
Although total ingress and egress are not big, we should keep these numbers in mind while designing our service.
Memory estimates: We can cache some of the hot pastes that are frequently accessed. Following the 80-20 rule, meaning 20% of hot pastes generate 80% of traffic, we would like to cache these 20% pastes
Since we have 5M read requests per day, to cache 20% of these requests, we would need:
0.2 * 5M * 10KB ~= 10 GB
- System APIs
We can have SOAP or REST APIs to expose the functionality of our service. Following could be the definitions of the APIs to create/retrieve/delete Pastes:
addPaste(api_dev_key, paste_data, custom_url=None user_name=None, paste_name=None, expire_date=None)
Parameters:
api_dev_key (string): The API developer key of a registered account. This will be used to, among other things, throttle users based on their allocated quota.
paste_data (string): Textual data of the paste.
custom_url (string): Optional custom URL.
user_name (string): Optional user name to be used to generate URL.
paste_name (string): Optional name of the paste expire_date (string): Optional expiration date for the paste.
api_dev_key (string): The API developer key of a registered account. This will be used to, among other things, throttle users based on their allocated quota.
paste_data (string): Textual data of the paste.
custom_url (string): Optional custom URL.
user_name (string): Optional user name to be used to generate URL.
paste_name (string): Optional name of the paste expire_date (string): Optional expiration date for the paste.
Returns: (string)
A successful insertion returns the URL through which the paste can be accessed, otherwise, returns an error code.
A successful insertion returns the URL through which the paste can be accessed, otherwise, returns an error code.
Similarly, we can have retrieve and delete Paste APIs:
getPaste(api_dev_key, api_paste_key)
Where “api_paste_key” is a string representing the Paste Key of the paste to be retrieved. This API will return the textual data of the paste.
deletePaste(api_dev_key, api_paste_key)
A successful deletion returns ‘true’, otherwise returns ‘false’.
- Database Design
A few observations about the nature of the data we are going to store:
- We need to store billions of records.
- Each metadata object we are going to store would be small (less than 100 bytes).
- Each paste object we are storing can be of medium size (it can be a few MB).
- There are no relationships between records, except if we want to store which user created what Paste.
- Our service is read-heavy.
Database Schema:
We would need two tables, one for storing information about the Pastes and the other for users’ data.

Here, ‘URlHash’ is the URL equivalent of the TinyURL and ‘ContentKey’ is the object key storing the contents of the paste.
- High Level Design
At a high level, we need an application layer that will serve all the read and write requests. Application layer will talk to a storage layer to store and retrieve data. We can segregate our storage layer with one database storing metadata related to each paste, users, etc., while the other storing the paste contents in some object storage (like Amazon S3 10). This division of data will also allow us to scale them individually.
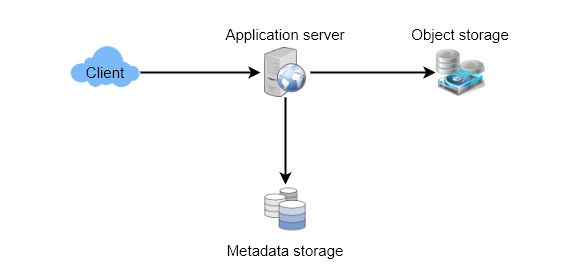
- Component Design
a. Application layer
Our application layer will process all incoming and outgoing requests. The application servers will be talking to the backend data store components to serve the requests.
How to handle a write request? Upon receiving a write request, our application server will generate a six-letter random string, which would serve as the key of the paste (if the user has not provided a custom key). The application server will then store the contents of the paste and the generated key in the database. After the successful insertion, the server can return the key to the user. One possible problem here could be that the insertion fails because of a duplicate key. Since we are generating a random key, there is a possibility that the newly generated key could match an existing one. In that case, we should regenerate a new key and try again. We should keep retrying until we don’t see failure due to the duplicate key. We should return an error to the user if the custom key they have provided is already present in our database.
Another solution of the above problem could be to run a standalone Key Generation Service (KGS) that generates random six letters strings beforehand and stores them in a database (let’s call it key-DB). Whenever we want to store a new paste, we will just take one of the already generated keys and use it. This approach will make things quite simple and fast since we will not be worrying about duplications or collisions. KGS will make sure all the keys inserted in key-DB are unique. KGS can use two tables to store keys, one for keys that are not used yet and one for all the used keys. As soon as KGS give some keys to an application server, it can move these to the used keys table. KGS can always keep some keys in memory so that whenever a server needs them, it can quickly provide them. As soon as KGS loads some keys in memory, it can move them to the used keys table, this way we can make sure each server gets unique keys. If KGS dies before using all the keys loaded in memory, we will be wasting those keys. We can ignore these keys given that we have a huge number of them.
Isn’t KGS single point of failure? Yes, it is. To solve this, we can have a standby replica of KGS, and whenever the primary server dies, it can take over to generate and provide keys.
Can each app server cache some keys from key-DB? Yes, this can surely speed things up. Although in this case, if the application server dies before consuming all the keys, we will end up losing those keys. This could be acceptable since we have 68B unique six letters keys, which are a lot more than we require.
How to handle a paste read request? Upon receiving a read paste request, the application service layer contacts the datastore. The datastore searches for the key, and if it is found, returns the paste’s contents. Otherwise, an error code is returned.
b. Datastore layer
We can divide our datastore layer into two:
- Metadata database: We can use a relational database like MySQL or a Distributed Key-Value store like Dynamo or Cassandra.
- Object storage: We can store our contents in an Object storage like Amazon’s S3. Whenever we feel like hitting our full capacity on content storage, we can easily increase it by adding more servers.
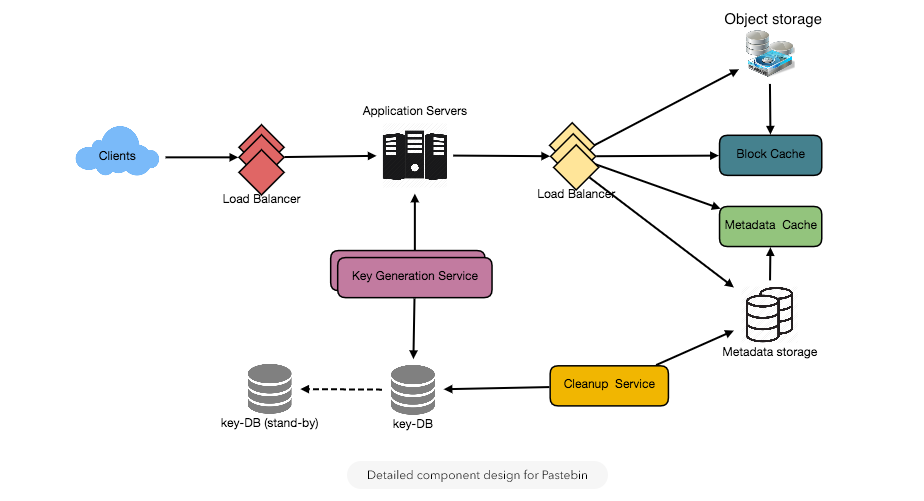
Detailed component design for Pastebin
- Purging or DB Cleanup
Please see Designing a URL Shortening service 118.
- Data Partitioning and Replication
Please see Designing a URL Shortening service 118.
- Cache and Load Balancer
Please see Designing a URL Shortening service 118.
- Security and Permissions
Please see Designing a URL Shortening service 118.
Thanks for sharing this valuable post! Teenyfy is fantastic for anyone looking to make links shorter. It's easy to use, and perfect for creating custom, branded URLs. Simplify your sharing and improve click-through rates with Teenyfy!
ReplyDeletehttps://www.teenyfy.com/
Teenyfy's Custom Name URL Shortener is a unique advantage! It makes interfaces simple to recollect and share. Ideal for marking and personalization. Strongly suggest for anybody requiring a dependable, adjustable URL shortening administration. Contact us for more!
ReplyDeletehttps://www.teenyfy.com/
At property investment consulting dubai, we specialize in Dubai property investment and are recognized as a leading authority in the Dubai real estate market.
ReplyDeleteGreetings from South East QLD Care! Being Top NDIS service provider in south east queensland means that we are dedicated to guiding people through the NDIS and enable independent, happy lives by means of tailored, high-quality support.
ReplyDeleteKlikSaku - One Link. Unlimited Earnings
ReplyDeleteMinifyLinks is a powerful platform offering the best URL shortner experience, allowing users to convert long links into short, clean, and shareable URLs. It provides advanced features like analytics, custom links, and secure redirection, making it ideal for marketers, businesses, and everyday users seeking fast, reliable link management.best url shortner
ReplyDeleteMinifyLinks is one of the best URL shortener tools for creating clean, short, and trackable links. It helps improve user experience, boost click-through rates, and simplify link sharing across platforms. With easy-to-use features and useful analytics, MinifyLinks is perfect for marketers, creators, and businesses aiming for better online performance.
ReplyDeleteurl shortener!
best url shortener!
custom best free url shortener!