Design Twitter
Designing Twitter
Let’s design a Twitter like social networking service. Users of the service will be able to post tweets, follow other people and favorite tweets. Difficulty Level: Medium
- What is Twitter?
Twitter is an online social networking service where users post and read short 140-character messages called “tweets”. Registered users can post and read tweets, but those who are not registered can only read them. Users access Twitter through their website interface, SMS or mobile app.
- Requirements and Goals of the System
We will be designing a simpler version of Twitter with following requirements:
Functional Requirements
- Users should be able to post new tweets.
- A user should be able to follow other users.
- Users should be able to mark tweets favorite.
- The service should be able to create and display user’s timeline consisting of top tweets from all the people the user follows.
- Tweets can contain photos and videos.
Non-functional Requirements
- Our service needs to be highly available.
- Acceptable latency of the system is 200ms for timeline generation.
- Consistency can take a hit (in the interest of availability), if a user doesn’t see a tweet for a while, it should be fine.
Extended Requirements
- Searching tweets.
- Reply to a tweet.
- Trending topics – current hot topics/searches.
- Tagging other users.
- Tweet Notification.
- Who to follow? Suggestions?
- Moments.
- Capacity Estimation and Constraints
Let’s assume we have one billion total users, with 200 million daily active users (DAU). Also, we have 100 million new tweets every day, and on average each user follows 200 people.
How many favorites per day? If on average each user favorites five tweets per day, we will have:
200M users * 5 favorites => 1B favorites
How many total tweet-views our system will generate? Let’s assume on average a user visits their timeline two times a day and visits five other people’s pages. One each page if a user sees 20 tweets, total tweet-views our system will generate:
200M DAU * ((2 + 5) * 20 tweets) => 28B/day
Storage Estimates Let’s say each tweet has 140 characters and we need two bytes to store a character without compression. Let’s assume we need 30 bytes to store metadata with each tweet (like ID, timestamp, user ID, etc.). Total storage we would need:
100M * (280 + 30) bytes => 30GB/day
What would be our storage needs for five years? How much storage we would need for users’ data, follows, favorites? We will leave this for exercise.
Not all tweets will have media, let’s assume that on average every fifth tweet has a photo and every tenth has a video. Let’s also assume on average a photo is 200KB and a video is 2MB. This will lead us to have 24TB of new media every day.
(100M/5 photos * 200KB) + (100M/10 videos * 2MB) ~= 24TB/day
Bandwidth Estimates Since total ingress is 24TB per day, this would translate into 290MB/sec.
Remember that we have 28B tweet views per day. We must show the photo of every tweet (if it has a photo), but let’s assume that the users watch every 3rd video they see in their timeline. So, total egress will be:
(28B * 280 bytes) / 86400s of text => 93MB/s
- (28B/5 * 200KB ) / 86400s of photos => 13GB/S
- (28B/10/3 * 2MB ) / 86400s of Videos => 22GB/s
Total ~= 35GB/s
- System APIs
 Once we’ve finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system.
Once we’ve finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system.
We can have SOAP or REST APIs to expose the functionality of our service. Following could be the definition of the API for posting a new tweet:
tweet(api_dev_key, tweet_data, tweet_location, user_location, media_ids, maximum_results_to_return)
Parameters:
api_dev_key (string): The API developer key of a registered account. This will be used to, among other things, throttle users based on their allocated quota.
tweet_data (string): The text of the tweet, typically up to 140 characters.
tweet_location (string): Optional location (longitude, latitude) this Tweet refers to. user_location (string): Optional location (longitude, latitude) of the user adding the tweet.
media_ids (number[]): Optional list of media_ids to be associated with the Tweet. (All the media photo, video, etc.) need to be uploaded separately.
api_dev_key (string): The API developer key of a registered account. This will be used to, among other things, throttle users based on their allocated quota.
tweet_data (string): The text of the tweet, typically up to 140 characters.
tweet_location (string): Optional location (longitude, latitude) this Tweet refers to. user_location (string): Optional location (longitude, latitude) of the user adding the tweet.
media_ids (number[]): Optional list of media_ids to be associated with the Tweet. (All the media photo, video, etc.) need to be uploaded separately.
Returns: (string)
A successful post will return the URL to access that tweet. Otherwise, an appropriate HTTP error is returned.
A successful post will return the URL to access that tweet. Otherwise, an appropriate HTTP error is returned.
- High Level System Design
We need a system that can efficiently store all the new tweets, 100M/86400s => 1150 tweets per second and read 28B/86400s => 325K tweets per second. It is clear from the requirements that this will be a read-heavy system.
At a high level, we need multiple application servers to serve all these requests with load balancers in front of them for traffic distributions. On the backend, we need an efficient database that can store all the new tweets and can support a huge number of reads. We would also need some file storage to store photos and videos.
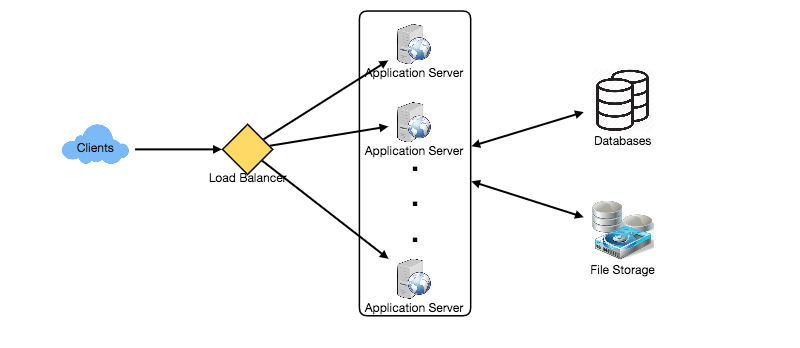
Although our expected daily write load is 100 million and read load is 28 billion tweets. This means, on average our system will receive around 1160 new tweets and 325K read requests per second. This traffic will be distributed unevenly throughout the day, though, at peak time we should expect at least a few thousand write requests and around 1M read requests per second. We should keep this thing in mind while designing the architecture of our system.
- Database Schema
We need to store data about users, their tweets, their favorite tweets, and people they follow.

For choosing between SQL and NoSQL databases to store the above schema, please see ‘Database schema’ under Designing Instagram 28.
- Data Sharding
Since we have a huge number of new tweets every day and our read load is extremely high too, we need to distribute our data onto multiple machines such that we can read/write it efficiently. We have many options to shard our data; let’s go through them one by one:
Sharding based on UserID: We can try storing all the data of a user on one server. While storing, we can pass the UserID to our hash function that will map the user to a database server where we will store all of the user’s tweets, favorites, follows, etc. While querying for tweets/follows/favorites of a user, we can ask our hash function where can we find the data of a user and then read it from there. This approach has a couple of issues:
- What if a user becomes hot? There could be a lot of queries on the server holding the user. This high load will affect the performance of our service.
- Over time some users can end up storing a lot of tweets or have a lot of follows compared to others. Maintaining a uniform distribution of growing user’s data is quite difficult.
To recover from these situations either we have to repartition/redistribute our data or use consistent hashing.
Sharding based on TweetID: Our hash function will map each TweetID to a random server where we will store that Tweet. To search tweets, we have to query all servers, and each server will return a set of tweets. A centralized server will aggregate these results to return them to the user. Let’s look into timeline generation example, here are the number of steps our system has to perform to generate a user’s timeline:
- Our application (app) server will find all the people the user follows.
- App server will send the query to all database servers to find tweets from these people.
- Each database server will find the tweets for each user, sort them by recency and return the top tweets.
- App server will merge all the results and sort them again to return the top results to the user.
This approach solves the problem of hot users, but in contrast to sharding by UserID, we have to query all database partitions to find tweets of a user, which can result in higher latencies.
We can further improve our performance by introducing cache to store hot tweets in front of the database servers.
Sharding based on Tweet creation time: Storing tweets based on recency will give us the advantage of fetching all the top tweets quickly, and we only have to query a very small set of servers. But the problem here is that the traffic load will not be distributed, e.g., while writing, all new tweets will be going to one server, and the remaining servers will be sitting idle. Similarly while reading, the server holding latest data will have a very high load as compared to servers holding old data.
What if we can combine sharding by TweedID and Tweet creation time? If we don’t store tweet creation time separately and use TweetID to reflect that, we can get benefits of both the approaches. This way it will be quite quick to find latest Tweets. For this, we must make each TweetID universally unique in our system, and each TweetID should contain timestamp too.
We can use epoch time for this. Let’s say our TweetID will have two parts; the first part will be representing epoch seconds and the second part will be an auto-incrementing sequence. So, to make a new TweetID, we can take the current epoch time and append an auto-incrementing number to it. We can figure out shard number from this TweetID and store it there.
What could be the size of our TweetID? Let’s say our epoch time starts today, how many bits we would need to store the number of seconds for next 50 years?
86400 sec/day * 365 (days a year) * 50 (years) => 1.6B
We would need 31 bits to store this number. Since on average we are expecting 1150 new tweets per second, we can allocate 17 bits to store auto incremented sequence; this will make our TweetID 48 bits long. So, every second we can store (2^17 => 130K) new tweets. We can reset our auto incrementing sequence every second. For fault tolerance and better performance, we can have two database servers to generate auto-incrementing keys for us, one generating even numbered keys and the other generating odd numbered keys.

If we assume our current epoch seconds are “1483228800”, our TweetID will look like this:
1483228800 000001
1483228800 000002
1483228800 000003
1483228800 000004
…
1483228800 000002
1483228800 000003
1483228800 000004
…
If we make our TweetID 64bits (8 bytes) long, we can easily store tweets for next 100 years and also store them for mili-seconds granularity.
- Cache
We can introduce a cache for database servers to cache hot tweets and users. We can use an off-the-shelf solution like Memcache that can store the whole tweet objects. Application servers before hitting database can quickly check if the cache has desired tweets. Based on clients’ usage pattern we can determine how many cache servers we need.
Which cache replacement policy would best fit our needs? When the cache is full, and we want to replace a tweet with a newer/hotter tweet, how would we choose? Least Recently Used (LRU) can be a reasonable policy for our system. Under this policy, we discard the least recently viewed tweet first.
How can we have more intelligent cache? If we go with 80-20 rule, that is 20% of tweets are generating 80% of read traffic which means that certain tweets are so popular that majority of people read them. This dictates that we can try to cache 20% of daily read volume from each shard.
What if we cache the latest data? Our service can benefit from this approach. Let’s say if 80% of our users see tweets from past three days only; we can try to cache all the tweets from past three days. Let’s say we have dedicated cache servers that cache all the tweets from all users from past three days. As estimated above, we are getting 100 million new tweets or 30GB of new data every day (without photos and videos). If we want to store all the tweets from last three days, we would need less than 100GB of memory. This data can easily fit into one server, but we should replicate it onto multiple servers to distribute all the read traffic to reduce the load on cache servers. So whenever we are generating a user’s timeline, we can ask the cache servers if they have all the recent tweets for that user, if yes, we can simply return all the data from the cache. If we don’t have enough tweets in the cache, we have to query backend to fetch that data. On a similar design, we can try caching photos and videos from last three days.
Our cache would be like a hash table, where ‘key’ would be ‘OwnerID’ and ‘value’ would be a doubly linked list containing all the tweets from that user in past three days. Since we want to retrieve most recent data first, we can always insert new tweets at the head of the linked list, which means all the older tweets will be near the tail of the linked list. Therefore, we can remove tweets from the tail to make space for newer tweets.
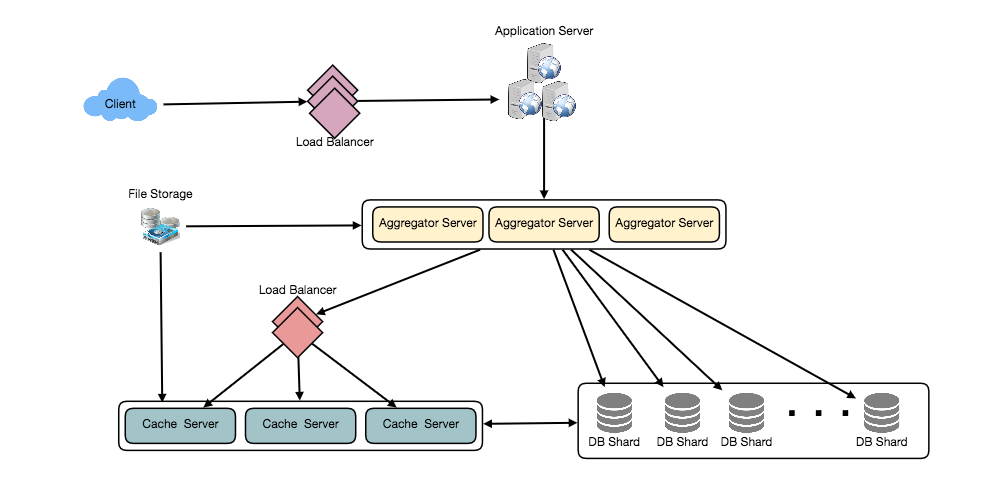
- Timeline Generation
For a detailed discussion about timeline generation, take a look at Designing Facebook’s Newsfeed 9.
- Replication and Fault Tolerance
Since our system is read-heavy, we can have multiple secondary database servers for each DB partition. Secondary servers will be used for read traffic only. All writes will first go to the primary server and then will be replicated to secondary servers. This scheme will also give us fault tolerance, as whenever the primary server goes down, we can failover to a secondary server.
- Load Balancing
We can add Load balancing layer at three places in our system 1) Between Clients and Application servers 2) Between Application servers and database replication servers and 3) Between Aggregation servers and Cache server. Initially, a simple Round Robin approach can be adopted; that distributes incoming requests equally among servers. This LB is simple to implement and does not introduce any overhead. Another benefit of this approach is if a server is dead, LB will take it out of the rotation and will stop sending any traffic to it. A problem with Round Robin LB is, it won’t take server load into consideration. If a server is overloaded or slow, the LB will not stop sending new requests to that server. To handle this, a more intelligent LB solution can be placed that periodically queries backend server about their load and adjusts traffic based on that.
- Monitoring
Having the ability to monitor our systems is crucial. We should constantly collect data to get an instant insight into how our system is doing. We can collect following metrics/counters to get an understanding of the performance of our service:
- New tweets per day/second, what is the daily peak?
- Timeline delivery stats, how many tweets per day/second our service is delivering.
- Average latency that is seen by the user to refresh timeline.
By monitoring these counters, we will realize if we need more replication or load balancing or caching, etc.
- Extended Requirements
How to serve feeds? Get all the latest tweets from the people someone follows and merge/sort them by time. Use pagination to fetch/show tweets. Only fetch top N tweets from all the people someone follows. This N will depend on the client’s Viewport, as on mobile we show fewer tweets compared to a Web client. We can also cache next top tweets to speed things up.
Alternately, we can pre-generate the feed to improve efficiency, for details please see ‘Ranking and timeline generation’ under Designing Instagram 28.
Retweet: With each Tweet object in the database, we can store the ID of original Tweet and not store any contents on this retweet object.
Trending Topics: We can cache most frequently occurring hashtags or searched queries in the last N seconds and keep updating them after every M seconds. We can rank trending topics based on the frequency of tweets or search queries or retweets or likes. We can give more weight to topics which are shown to more people.
Who to follow? How to give suggestions? This feature will improve user engagement. We can suggest friends of people someone follows. We can go two or three level down to find famous people for the suggestions. We can give preference to people with more followers.
As only a few suggestions can be made at any time, use Machine Learning (ML) to shuffle and re-prioritize. ML signals could include people with recently increased follow-ship, common followers if the other person is following this user, common location or interests, etc.
Moments: Get top news for different websites for past 1 or 2 hours, figure out related tweets, prioritize them, categorize them (news, support, financials, entertainment, etc.) using ML – supervised learning or Clustering. Then we can show these articles as trending topics in Moments.
Search: Search involves Indexing, Ranking, and Retrieval of tweets. A similar solution is discussed in our next problem Design Twitter Search 27.
Its such as you read my mind! You appear to understand a lot about this, like you wrote the e-book in it or something. I believe that you simply could do with a few % to force the message house a bit, however other than that, this is wonderful blog. A great read. I'll certainly be back. Insta stories
ReplyDeleteWhat is an outstanding post! “I’ll be back” (to read more of your content). Thanks for the nudge! Mark Lutchman
ReplyDeleteActually i didn't really get it when you talk about the advantages of sharding by both epoch timestamp and sequence, could you get further in this part specifically?
ReplyDeleteCuz in my mind, if you use this way to search for the tweets of some guy, you just still need to query all the replication of the databases. i don't see the differences between this way and sharding by tweetID way.
I would appreciate if you could give more explanation.
Did not get that part either, maybe some one could please clarify?
DeleteI really appreciate the kind of topics you post here. Thanks for sharing us a great information that is actually helpful. Good day! top twitter trends
ReplyDeleteTwist by ibmseo Excellent read, Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.
ReplyDelete